Patterns for Resilient Systems
Speaker: Kanin Chotvorrarak (DailiTech)
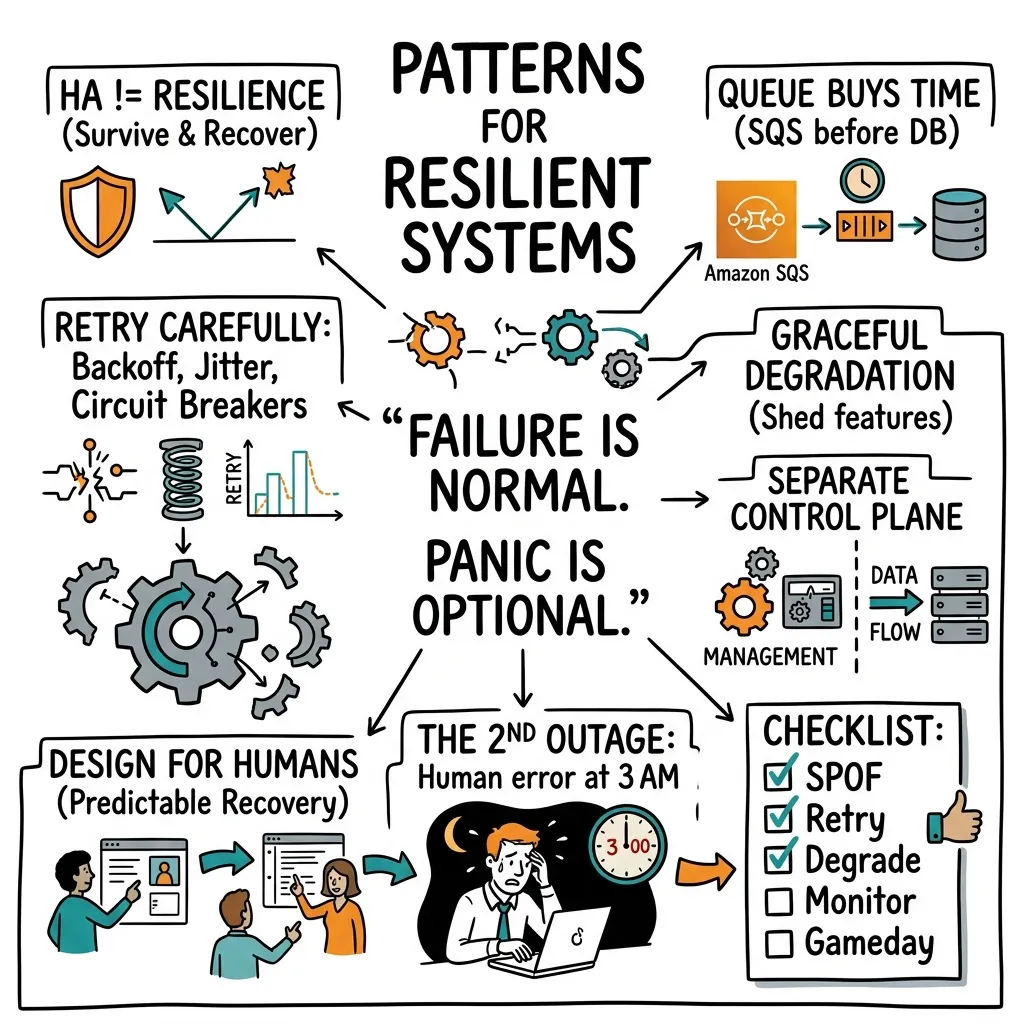
“Failure is normal. Panic is optional.”
High Availability vs. Resilience
- Highly Available
\neqResilient: High availability is about redundancy and uptime percentages. Resilience is about people and systems understanding their application and architecture to survive and recover from failures. - Hidden Dependencies: Most catastrophic outages come from hidden dependencies, such as a shared database, a single auth service, or a single NAT gateway.
- Simplicity Wins: Keep services simple. Running 4 decoupled services is far more resilient than running 12 highly complex, tightly coupled microservices.
Architectural Resilience Patterns
Pattern 1: Queue Buys Time
- Concept: Absorb traffic spikes and prevent cascading failures by inserting a message queue (e.g., SQS) in front of slow operations (e.g., database writes).
- Benefit: Decouples the ingestion speed from database write capacity.
Pattern 2: Retry Carefully
- Problem: Trivial retry loops can create a self-inflicted Distributed Denial of Service (DDoS) on your databases or downstream services during a partial outage.
- Solution:
- Exponential Backoff: Increase the wait time between retries.
- Jitter: Add random noise to retry intervals to prevent “thundering herd” patterns.
- Circuit Breakers: Tripping a circuit breaker stops requests from hitting a failing downstream dependency completely, letting it recover.
Pattern 3: Graceful Degradation
- Concept: Disable non-essential features (e.g., product recommendations or user reviews) to save compute capacity when the core database is under heavy load.
- Implementation: Use feature flags (e.g., using AWS AppConfig) to toggle off non-critical code paths instantly.
Pattern 4: Separate the Control Plane
- Concept: Isolate operational utilities from the data plane.
- Pitfall: Do not run CI/CD systems, administration tools, or heavy monitoring scrapers in the same production cluster. A failure in your monitoring script should never crash your production service.
Pattern 5: Design for Humans & Predictability
- Concept: Reduce cognitive load. Imagine an engineer trying to debug a complex system at 3 AM.
- Approach: Make the recovery path highly predictable and automated where possible. Keep operational playbooks clean.
Pattern 6: Recovery Architecture
- Concept: Architect explicitly for the recovery phase. Test how systems boot up, re-populate caches, and handle backlogged messages when recovering from an outage.
Production Resilience Checklist

| Check | Item | Key Diagnostic Question |
|---|---|---|
| SPOF | Single Point of Failure | Can any single component take down the entire system? |
| RETRY | Retry Mechanics | Do retries have backoff, jitter, and circuit breakers? |
| DEGRADE | Graceful Degradation | Can your system shed non-critical features under load? |
| HUMAN | Operational Load | Can your team safely recover the system at 3 AM? |
| MONITOR | Alerts | Are your alerts actionable, or just noisy? |
| GAMEDAY | Chaos Engineering | When did you last practice failure in production? |
“If you can’t answer these confidently — start today.”
The Human Factor: The “Second Outage”
A critical resilience insight: the second outage is often human-caused. When a system fails (the first outage), engineers are placed under extreme stress. Panic, rushed terminal commands, and lack of sleep lead to human errors that trigger a second, often more severe outage. Resilient design aims to protect engineers from making these fatal mistakes by simplifying recovery.